Why I hate Jenkins


According to its website, Jenkins is “the leading open-source automation server.” Development teams use Jenkins to turn chunks of code into software, to move those pieces of software around, and to explain to the team what happened … or what should have happened but didn’t.
Does your website consist of two front-end repositories and a back-end database? Do you have a testing environment, a staging environment, and the live production environment? There’s a really good chance that Jenkins is the tool that your team uses to move code from place to place.
And there’s a good chance that your team hates everything about it.
The problem isn’t Jenkins. The problem is looking at me in the mirror.
If you Google “I hate Jenkins” or “Jenkins problems” or any variety of that, the very first comment or reply you will see is a Jenkins advocate with ruffled feathers saying “Software isn’t the problem. Inappropriate use of the software is the problem. Insufficient discipline is the problem. If you have a problem with Jenkins, you are the problem.”
These people are not wrong, and I sympathize with them. Open-source software, in general, is important and wonderful. Jenkins has been built with care and love by many users who selflessly donate their time and expertise. The solutions to issues uncovered by Jenkins have been foundational in a whole new class of tools.
But the thing is … Jenkins makes it almost impossible to resist the temptation of becoming a deployment criminal.
I don’t hate Jenkins in theory. I hate Jenkins in practice—every instance of Jenkins that I have ever had to work with.
Jenkins creates bottlenecks, gatekeepers, and big bang deployments
When a team doesn’t have both iron discipline and sufficient time to do things right the first time, three problems seem to emerge every time:
Bottlenecks in development skillset
Setting up your first Jenkins instance can be done in a weekend, and “happy path” deployments are straightforward. “Take THIS and put it over THERE, then report the results at THIS internal web page!”
The learning curve and specific skillset increases exponentially as you use it. How many people on your team have a full vanilla XML parser already set up in their VS Code? Maybe the answer is “most of them.” But how many people on your team can write in Groovy without ninety minutes of Googling?
As soon as you have a working instance of Jenkins, you can only make changes as quickly as the person who set it up has time to apply their newly acquired skills. In my own experience, that creates an instantaneous bottleneck—one that only gets worse with time.
And as your system naturally gets more complex—a Redis cache here, an integration with a component library there—the bottlenecks compound.
Developers become gatekeepers
The developer with the domain-specific knowledge has to become a gatekeeper, pushing back on changes or updates because there’s just not enough time.
Idea: “Can we get the Jenkins reporting page off of :8080 and available to the outside world, so that developers outside the network can see what’s deployed to the QA environment?”
Reality: “In order to do that, I need to connect Jenkins to our Azure IAM solution, and, er … maybe I can do that when things are slow over the holidays?”
Now you have a skill bottleneck and a reluctant gatekeeper—creating a lot of steps that can lead to confusion.
Forced big bang deployments
If your deployment reporting is on a Jenkins server hosted in your environment, it’s likely that your growing team—some behind a firewall, some outside the network—don’t all have good visibility about what has been deployed where, when.
That means that conversations that should happen right away wait until the next day’s standup. “Well, QA looks weird, but I don’t know if my code is there, so I’ll wait and see.”
“Jenkins allows developers to cosplay as a DevOps engineer. But Jenkins by itself doesn’t provide the time, skills, and resources to be a good DevOps engineer.”
Continuous deployment should be immediate and autonomous
To me, the main point of continuous deployment is to stop people from “hopping on quick calls.” Let me show a recent, real-life example of how continuous integration should work.
At 10:30 AM, Think developer Christine Martino adds a feature to a Storybook pattern library. She pushes her feature branch to the upstream repository. Netlify is watching the repository, detects the new branch, and builds a deploy preview. Or at least it tries to build a preview—but fails.
Netlify announces the failure to the Slack channel where bot-spam goes:
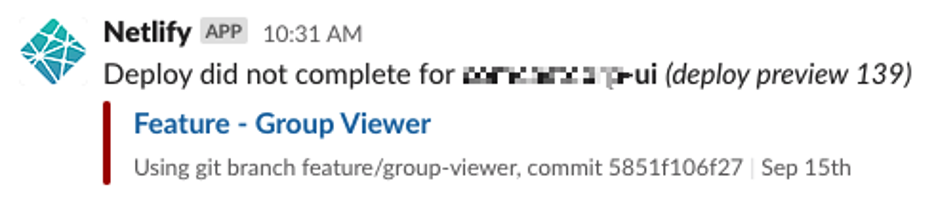
“Huh,”—thinks Christine to herself. “I wonder what happened?” and kicks off the build again, but has no luck:
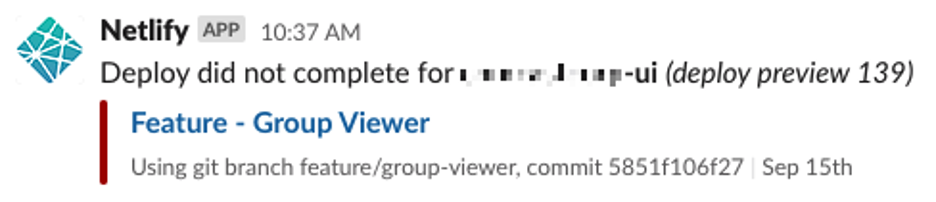
So far, six minutes have elapsed. Christine knows that this branch isn’t working and that it’s not due to other people’s work. So she reflects for a brief moment. Then the light dawns:

Christine rebases against the main branch, updating the visual-regression test dependency for Percy. She pushes her work upstream, and voila!
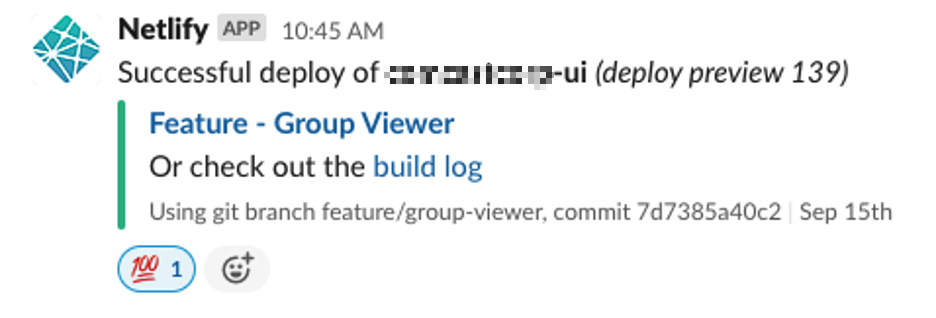
SUCCESS. The feature branch is deployed, verified working, preview-able, and available to other team members.
Over the course of these seven minutes:
-
- Number of team members polled to ask if anything is weird with the environment: zero
- Number of Slack threads started to ask what branch is on the QA server: zero
- Number of DevOps threads started asking about if there’s anything different with the environment: zero
- Number of “quick calls” hopped on: zero
All of the above could have been done successfully with Jenkins. Specifically, with the help of a full-time, fully-trained Jenkins expert. Someone who has tuned Jenkins to the point that it can observe repositories, provision environments based on new branches, build those environments—and then report on the results directly in the place where the developers are already present (in this case, Slack.) But nobody ever gives DevOps the time they need to do it that way.
In my experience, the amount of time allocated to Jenkins configuration would have gotten the above flow as far as “Jenkins will fail silently—lighting a small red error light twelve panels deep inside a site on port 8080 that nobody outside the firewall can see.”
Someday, I will be introduced to an instance of Jenkins that has been maintained with perfect discipline. That has comprehensive, up-to-date documentation. That is simple to operate, straightforward to extend, and reports what it is doing in a way that is easy to understand.
So where do we go from here?
The moral of this story is that there is absolutely no substitute for true DevOps expertise. That DevOps expertise might come from fully-allocated experts inside your organization with enough time to get things right. That DevOps expertise might come from third-party tools that snap together and are maintained, extended, and supported by that third party’s team (we increasingly use Netlify and Github actions at Think.)
When you don’t take DevOps seriously—by attempting to configure CD without sufficient resources to do it right—the resulting tech debt starts at “terrible” and quickly mounts to “overwhelming.” Jenkins is an enabler—an attractive nuisance that lets you get into this situation quickly.
I hate it. And when I get into that situation, I hate myself.
Let’s do better!
We’re passionate about development standards and practices, and we’re passionate about giving developers the tools and the resources they need to work collaboratively. (Especially if that tool is Jenkins.) If you need support with an upcoming technology project or auditing your existing site, contact us today!


